Abstract
Fine-tuning-based adaptation is widely used to customize diffusion-based image generation, leading to large collections of community-created adapters that capture diverse subjects and styles. Adapters derived from the same base model can be merged with weights, enabling the synthesis of new visual results within a vast and continuous design space. To explore this space, current workflows rely on manual slider-based tuning, an approach that scales poorly and makes weight selection difficult, even when the candidate set is limited to 20-30 adapters. We propose GimmBO to support interactive exploration of adapter merging for image generation through Preferential Bayesian Optimization (PBO). Motivated by observations from real-world usage, including sparsity and constrained weight ranges, we introduce a two-stage BO backend that improves sampling efficiency and convergence in high-dimensional spaces. We evaluate our approach with simulated users and a user study, demonstrating improved convergence, high success rates, and consistent gains over BO and line-search baselines, and further show the flexibility of the framework through several extensions.
Motivation
Large online community merging image generation adapters to create new styles.
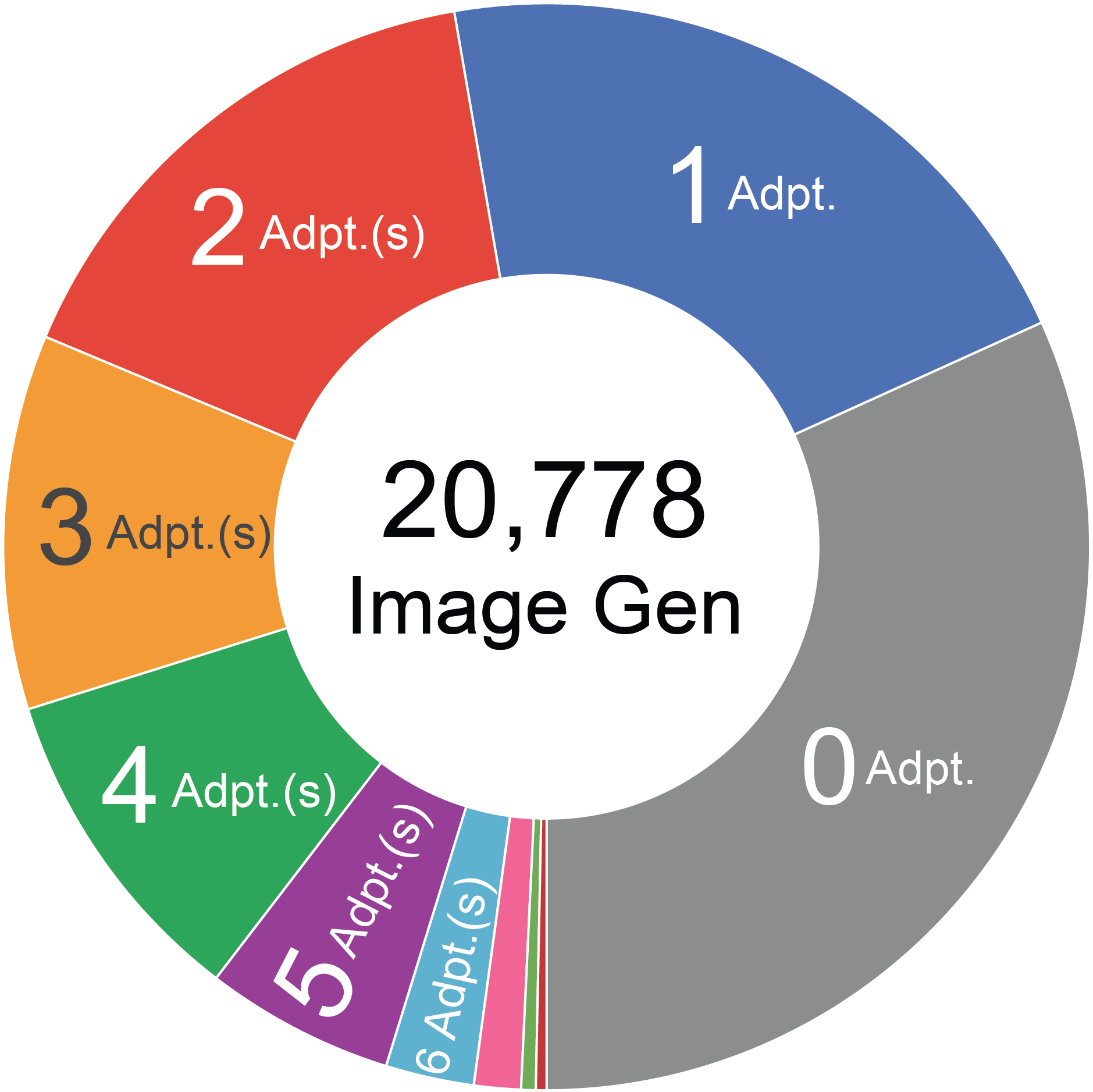
Merging with sliders is inefficient for >5~10 adapters.
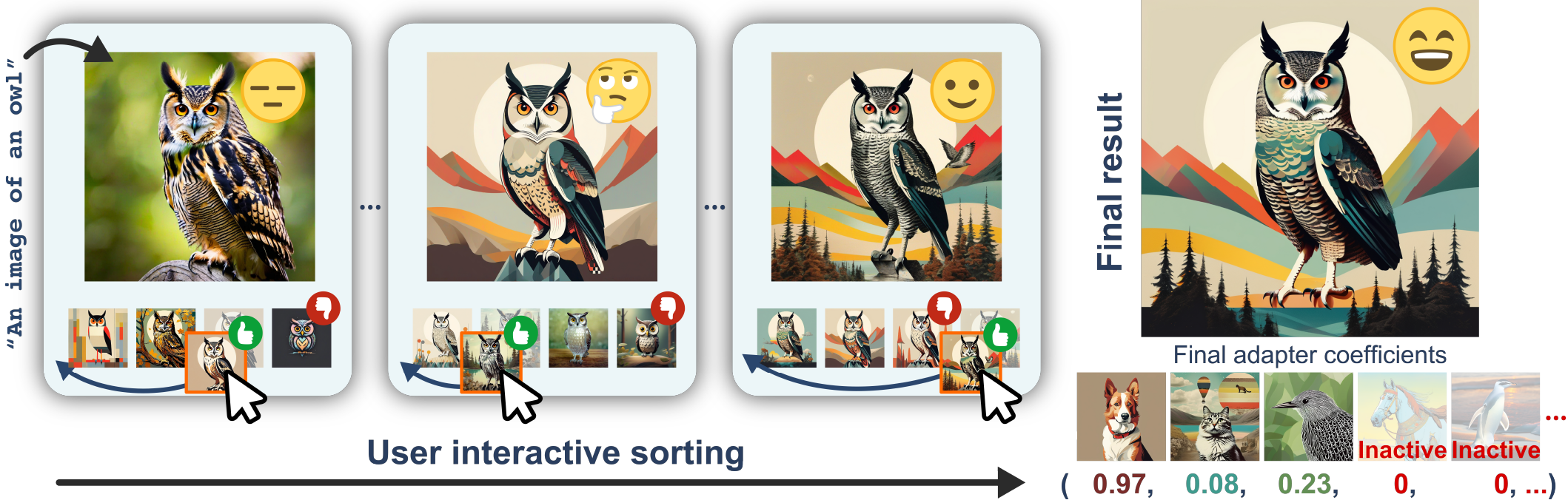
Method: Two-stage Interactive Adapter Merging via Preferential Bayesian Optimization (PBO).
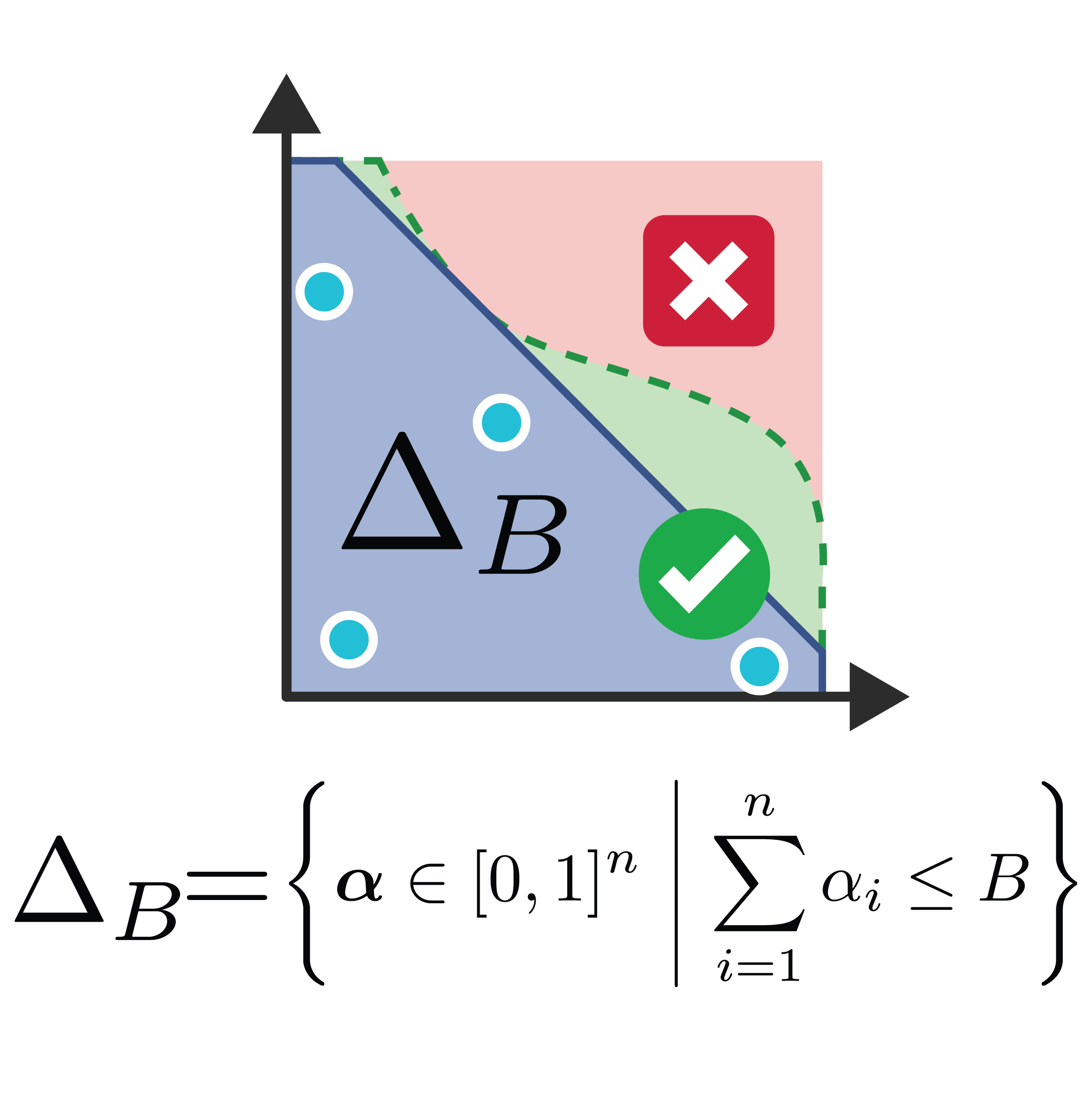
Stage One: GimmBO iteratively proposes new sample batches via PBO over a magnitude-constrained weight space.
Stage Two: Extracts sparsity pattern of the current top-k adapters and proceed to final result.

During both stages, user interactively ranks the proposed candidate images to update the PBO backend.
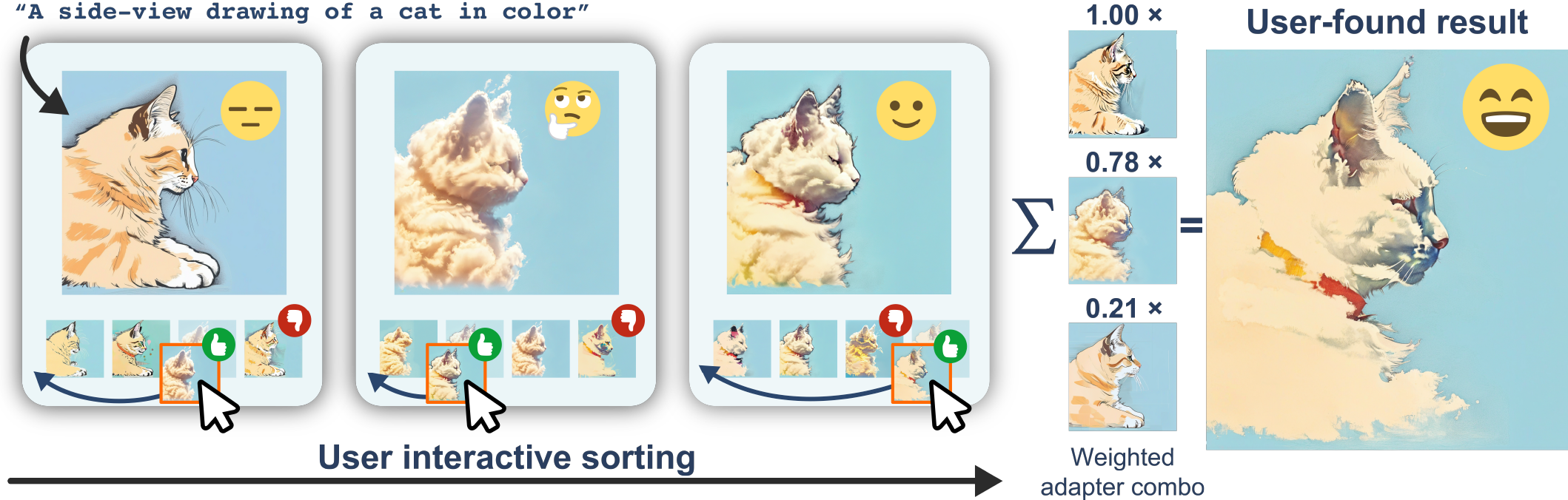
Results
We evaluate our approach through quantitative experiments with both simulated and real users.
Simulated Users
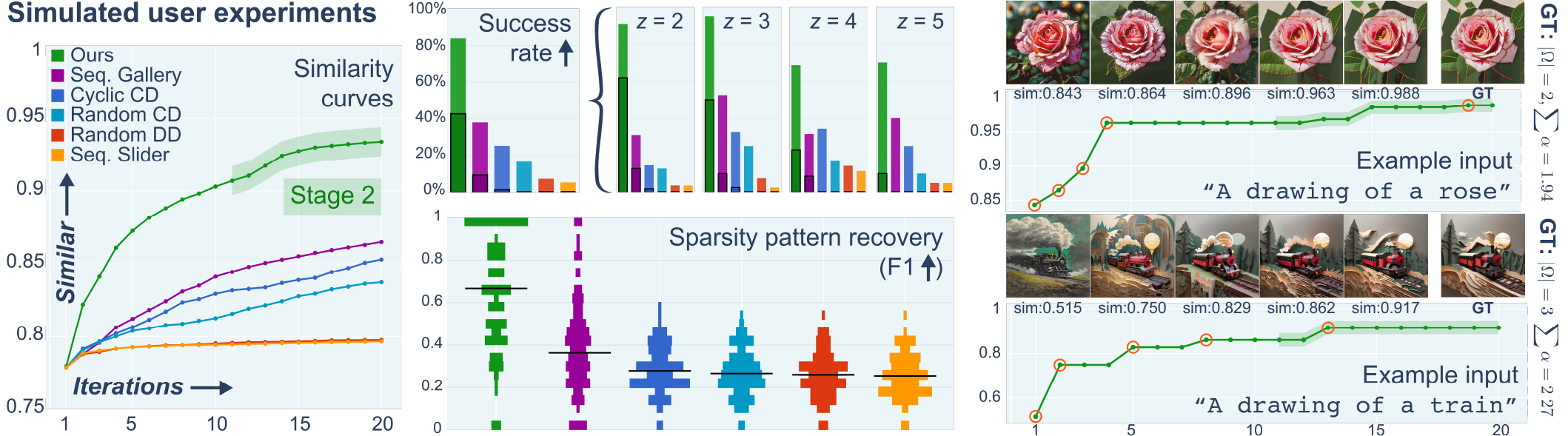
Running-best similarity curves averaged over 30 prompt-weight combinations and 5 random seeds, together with success rates and sparsity recovery (F1; black horizontal lines indicate the median) of the final best result. Success rates are first reported overall and then broken down by the ground-truth number of active adapters 𝑧, measured at a similarity threshold of 0.9 (solid bars), with darker outlines indicating cases exceeding 0.95. Curves are shown for two individual test inputs, with images corresponding to the highlighted iterations (orange circles).
Real Users
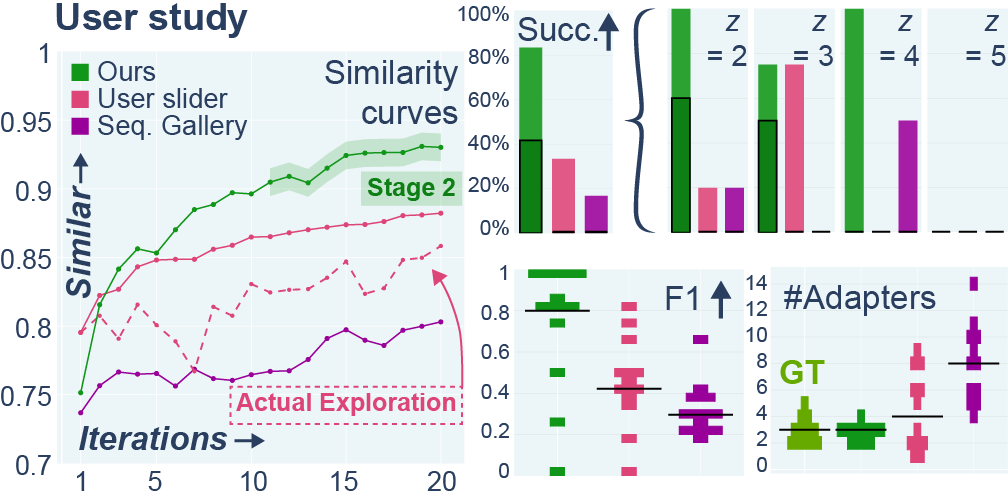
Running-best similarities averaged over 12 input-user combinations.For the slider interface, both running-best (solid) and explored intermediate results (dashed) are shown. We report success rates (> 0.9 in solid and > 0.95 outlined), sparsity recovery (F1; black lines indicate the median), and the number of active adapters, with ground truth indicated.
Extensions
Scaling to Large Adapter Collections via Retrieval

Real-world community adapter libraries far exceed the 20–30 dimensions GimmBO operates over. To bridge this gap, we integrate GimmBO with retrieval-based methods such as Stylus [Luo et al. 2024], which automatically selects 20–30 relevant adapters for a given prompt from thousands of community-created options. Simply averaging the retrieved adapters yields weak, under-specified results. Stylus's own fine merging produces a single fixed output that is better aligned with the prompt, but with no room for user control. GimmBO enables users to interactively explore the merged space, generating results that are better aligned with the prompt and significantly diverse.
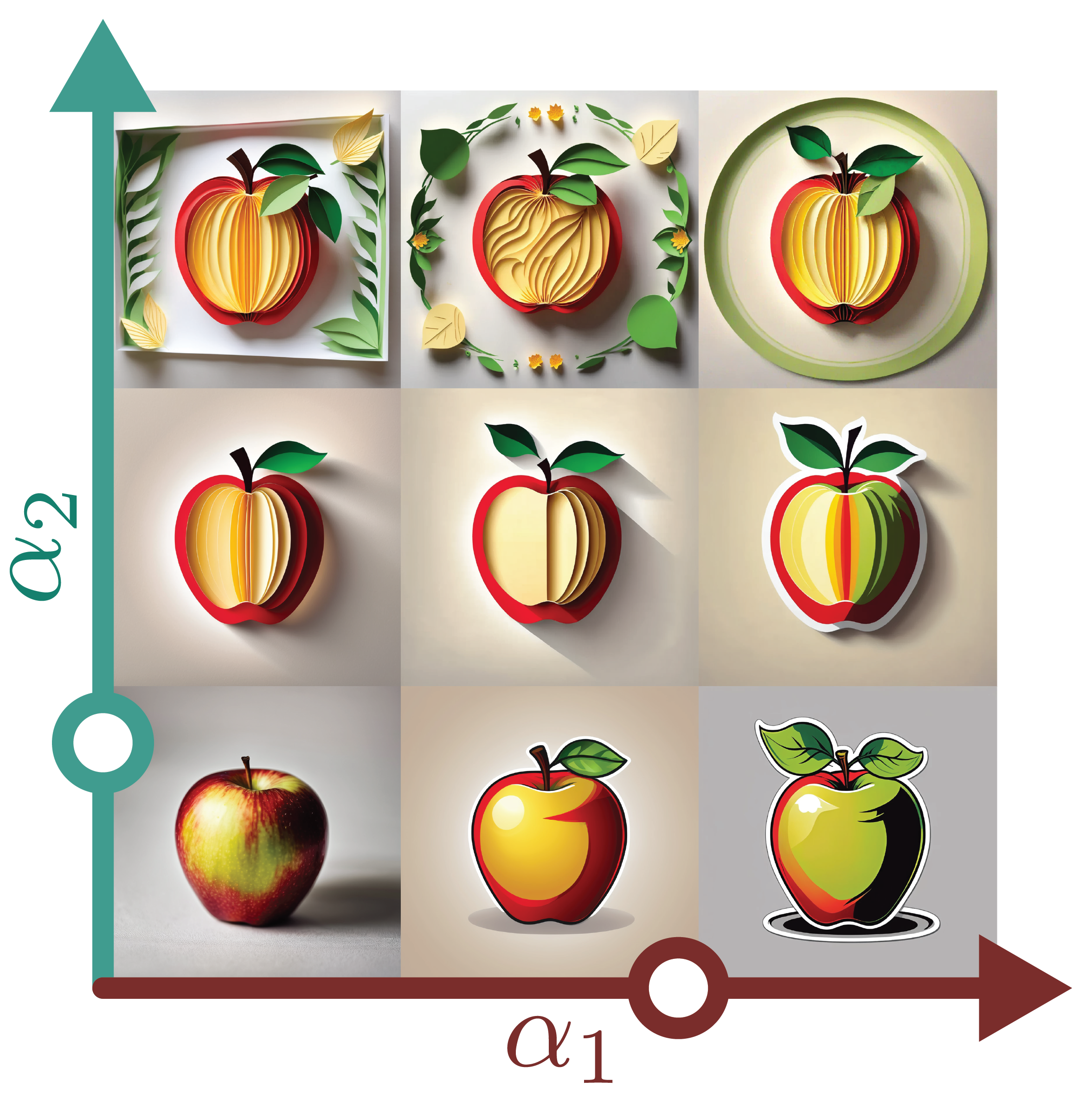
Content Merging

Appearance matching to a reference (left, GT) and diverse appearances generated by merging external appearance attributes such as hair, glasses, and expressions (right, indicated by various single-adapter generations), demonstrating generalization beyond style.
Reusable Stylization
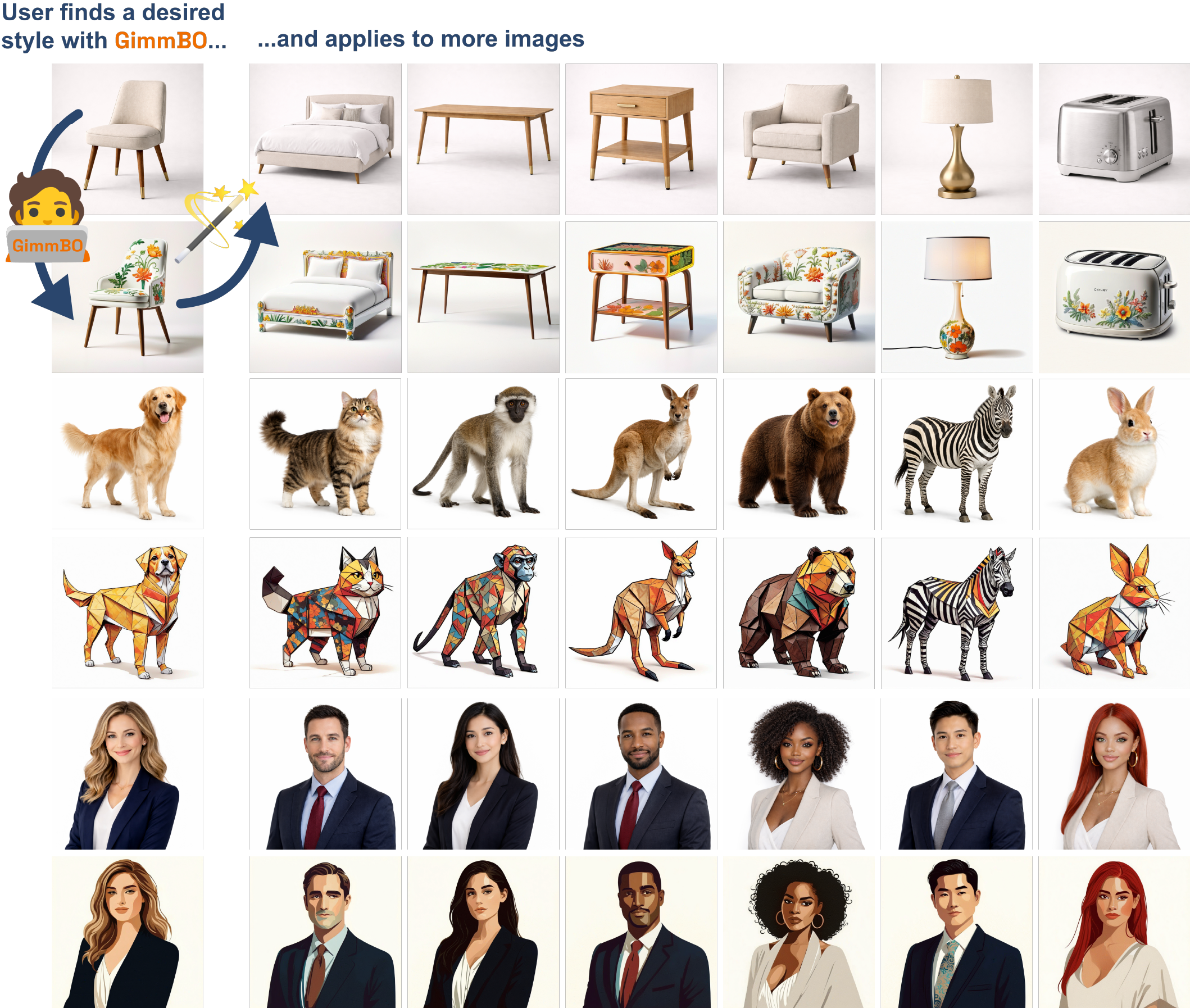
Applying a user-identified adapter merging configuration discovered with GimmBO to new inputs via SDEdit achieves consistent stylization across images. All styles shown are discovered by real users; control images here are generated using ChatGPT, but can be arbitrary user-provided images.
Acknowledgements
We thank Yuki Koyama for clarifications on prior work, Leping Qiu for assistance with user study design, all anonymous participants in our pilot and final studies, and the DGP members at the University of Toronto for discussions and support. Our research is funded in part by NSERC Discovery (RGPIN–2022–04680), the Ontario Early Research Award program, the Canada Research Chairs Program, a Sloan Research Fellowship, the DSI Catalyst Grant program, Arts & Science Postdoctoral Fellowship at the University of Toronto, and gifts by Adobe Inc.
Citation
Seq. Slider: Koyama, Yuki, et al. "Sequential line search for efficient visual design optimization by crowds." ACM Transactions on Graphics (TOG) 36.4 (2017): 1-11.
Stylus: Luo, Michael, et al. "Stylus: Automatic adapter selection for diffusion models." Advances in Neural Information Processing Systems 37 (2024): 32888–32915. https://stylus-diffusion.github.io/
